משפט מייהיל-נרוד - נקודת מבט נוספת, ואלגוריתמי מינימיזציה
בכל הנושא של תורת השפות הפורמליות, המשפט החביב עלי הוא משפט מייהיל-נרוד. כל כך חביב עלי, שבפוסט הזה אני הולך להציג אותו שוב, ובצורה שונה מזו שבה הצגתי אותו בפוסט הקודם שלי בנושא. שתי נקודות המבט על המשפט הן דואליות באופיין (הן אומרות את אותו הדבר, אבל כל אחת מסתכלת על הדבר הזה מנקודת מבט שונה ואפילו מנוגדת קצת), וזו שאציג עכשיו תהיה שימושית בהמשך, עם עוד כמה תוצאות יפות שאני רוצה להראות. בפרט, היא תהיה שימושית כדי לטפל בבעיה שעד כה לא התייחסתי אליה - איך אפשר למצוא בפועל את האוטומט המינימלי עבור שפה שמשפט מייהיל-נרוד מבטיח את קיומו. אראה שני אלגוריתמים שעושים את זה - הראשון הוא נחמד ואינטואיטיבי יחסית, והשני הוא משהו פסיכי לחלוטין: כשראיתי אותו בפעם הראשונה התגובה שלי הייתה “מה, לעזאזל?!”. הטיזר הזה מספיק לכם כדי שיתחשק לכם לראות איך אני מנסח מחדש את כל המונחים של נרוד בלשון אחרת? אחלה.
נתחיל בתזכורת מה הולך במשפט מייהיל-נרוד. בהינתן שפה \( L \) כלשהי מעל \( \Sigma^{*} \), הגדרנו יחס שקילות \( R_{L} \) מעל \( \Sigma^{*} \): \( xR_{L}y \) אם ורק אם לא קיימת “סיפא מפרידה” של \( x,y \) ביחס ל-\( L \), כלומר לכל \( z\in\Sigma^{*} \) מתקיים \( xz\in L\iff yz\in L \). סימנו את אוסף מחלקות השקילות של היחס הזה ב-\( \Sigma^{*}/R_{L} \), והמשפט אמר ש-\( L \) רגולרית אם ורק אם מספר מחלקות השקילות של היחס הוא סופי. האינטואיציה היא שניתן לבנות אוטומט (לאו דווקא סופי) עבור \( L \) שמצביו הם בדיוק \( \Sigma^{*}/R_{L} \), המצב ההתחלתי שלו הוא \( \left[\varepsilon\right] \) (מחלקת השקילות של \( \varepsilon \)), מצביו המקבלים הם מהצורה \( \left[w\right] \) עבור כל \( w\in L \), ופונקציית המעברים שלו היא \( \delta\left(\left[w\right],\sigma\right)=\left[w\sigma\right] \). הוכחנו שהאוטומט הזה הוא בעל מספר המצבים המינימלי מבין כל האוטומטים עבור \( L \), ולכן \( L \) הייתה רגולרית אם ורק אם המספר המינימלי הזה היה סופי.
עכשיו בואו נתאר את כל העסק הזה מזווית ראייה אחרת. אני הולך להשתמש במושג שהזכרתי קודם אבל לא קיבל עד כה את הזרקור שמגיע לו - המושג של חלוקה של שפות. נתחיל הפעם דווקא עם חלוקה במילה בודדת, ועם סימון חדש כדי להציג את זה. אם \( w=uv \) היא מילה ש-\( u \) היא רישא שלה, אז אסמן \( u^{-1}w\triangleq v \). כלומר, \( u^{-1}w \) היא מה שמקבלים מ-\( w \) אחרי שמסלקים ממנו את הרישא \( u \). האינטואיציה לסימון הזה עם החזקה של המינוס 1 מגיעה מתורת החבורות, ולא אכביר עליה מילים. צריך להיזהר קצת עם הסימון - אם \( u \) איננה רישא של \( w \), אז אין שום משמעות לסימון \( u^{-1}w \) בהקשר שלנו. כמו כן, באופן דומה אפשר גם להגדיר \( wu^{-1} \) אבל לא אזדקק לסימון הזה ולכן לא אציג אותו בהמשך.
עכשיו, אם \( L \) היא שפה כלשהו, אפשר להכליל את פעולת החלוקה עבורה: להגדיר \( u^{-1}L\triangleq\left\{ u^{-1}w\ |\ w\in L\right\} \), כאשר המוסכמה כאן היא שאם \( u^{-1}w \) אינו מוגדר הוא אינו משתתף בקבוצה (מבחינה פורמלית הסימון שלי לא תקין והייתי צריך להוסיף במפורש את התנאי ש-\( u \) היא רישא של \( w \), אבל אני בכוונה משתמש פה בסימון לא תקין - מה שנקרא Abuse of notation - כי חשוב לי להדגיש שככה זה עובד במתמטיקה - יותר חשובה לנו נוחות הסימון כל עוד כולם מבינים את הכוונה, מאשר נוקדנות ברמת הסימונים). גם את זה אפשר להכליל ולקבל חלוקה משמאל של שפות כדי שהגדרתי אותה פעם: \( L_{2}^{-1}L_{1}\triangleq\left\{ u^{-1}w\ |\ u\in L_{2},\in L_{1}\right\} \), אבל לא אזדקק לסימון הזה יותר מדי הפעם.
עכשיו אפשר לנסח את משפט מייהיל-נרוד בטרמינולוגיה החדשה שלנו: שפה \( L \) היא רגולרית אם ורק אם הקבוצה \( \left\{ u^{-1}L\ |\ u\in\Sigma^{*}\right\} \) סופית; וגודל הקבוצה שווה למספר המצבים באוטומט סופי דטרמיניסטי מינימלי עבור \( L \).
במבט ראשון אולי לא ברור מה הקשר, אבל במבט שני די ברור שזה בדיוק אותו דבר: דרך אחרת ושקולה לנסח את הטענה ש-\( xR_{L}y \) היא לומר ש-\( x^{-1}L=y^{-1}L \) - כלומר, שאוסף כל המילים \( z \) כך ש-\( xz\in L \) שווה לאוסף כל המילים כך ש-\( yz\in L \). אז עד כה לא עשיתי כלום חוץ מאשר הצבעה על העובדה (הנחמדה) שאפשר לנסח את המשפט בעזרת מושג החלוקה, במקום להזדקק למחלקות שקילות.
עכשיו בואו נכניס אוטומטים לתמונה. ניקח אוטומט סופי דטרמיניסטי כלשהו \( A=\left(Q,\Sigma,q_{0},\delta,F\right) \). עכשיו, לכל מצב \( q\in Q \) בואו נסמן ב-\( L_{q} \) את שפת כל המילים שאם אנחנו נמצאים ב-\( q \) וקוראים אותן, נגיע למצב מקבל: \( L_{q}\triangleq\left\{ w\in\Sigma^{*}\ |\ \hat{\delta}\left(q,w\right)\in F\right\} \). בבירור \( L\left(A\right)=L_{q_{0}} \) (אם זה לא ברור נסו להסביר לעצמכם את ההגדרה). עכשיו, לפני שנמשיך, אני רוצה להציג סימון שיחסוך לי את הצורך לכתוב \( \hat{\delta} \) עם סוגריים כל הזמן: במקום לכתוב \( \hat{\delta}\left(q,w\right) \) אני אכתוב \( q\cdot w \). פורמלית, אפשר לחשוב על זה כאילו \( w \) פועלת על \( q \), למי שמכיר את המושג הזה (כאן זו פעולה של המונואיד \( \Sigma^{*} \) על הקבוצה \( Q \), למי שמכיר את ההגדרות). התכונה שמעניינת אותנו כאן היא ש-\( q\cdot\left(uv\right)=\left(q\cdot u\right)\cdot v \) (מה שהוכחתי בעבר בתור \( \hat{\delta}\left(q_{0},uv\right)=\hat{\delta}\left(\hat{\delta}\left(q_{0},u\right),v\right) \)) ובגללה בחרתי את הסימון בצורה שבה בחרתי (נראה לי בהתחלה יותר טבעי לסמן \( w\cdot q \), אבל אני רוצה להימנע מזוועות כמו \( \left(uv\right)\cdot q=v\cdot\left(u\cdot q\right) \)). בסימון הזה, \( L_{q}\triangleq\left\{ w\in\Sigma^{*}\ |\ q\cdot w\in F\right\} \)
בואו נניח שכל המצבים ב-\( A \) ישיגים (לאוטומט כזה אקרא נגיש), כי קל להעיף מאוטומט מצבים לא ישיגים ומקבלים אוטומט שקול. זה אומר שלכל \( q \) קיימת מילה \( u \) כך ש-\( q=q_{0}\cdot u \). אני טוען ש-\( L_{q}=u^{-1}L \), ודי קל לראות את זה: \( w\in u^{-1}L \) אם ורק אם \( uw\in L \), אם ורק אם \( q_{0}\cdot uw\in F \), אם ורק אם \( \left(q_{0}\cdot u\right)\cdot w=q\cdot w\in F \), אם ורק אם \( w\in L_{q} \). באופן דומה, אם \( q=q_{0}\cdot v \) עבור \( v\ne u \) אז נקבל ש-\( L_{q}=v^{-1}L \) ולכן בפרט \( u^{-1}L=v^{-1}L \). המסקנה היא שהפונקציה \( f\left(q\right)=L_{q} \) היא פונקציה מ-\( Q \) על הקבוצה \( \left\{ u^{-1}L\ |\ u\in\Sigma^{*}\right\} \), כלומר הגודל של \( Q \) הוא לפחות כגודל הקבוצה הזו, ומכאן שמספר המצבים באוטומט שבונים בהוכחת מייהיל-נרוד הוא אכן מינימלי (כי מספר מצביו שווה לגודל הקבוצה \( \left\{ u^{-1}L\ |\ u\in\Sigma^{*}\right\} \)).
עכשיו, נניח שיש לנו שני מצבים \( q,p \) כך ש-\( L_{q}=L_{p} \). מה זה אומר? זה אומר ששני חישובים, שאחד מהם הגיע אל \( q \) והשני הגיע אל \( p \), יהיו משם והלאה שקולים במובן מסויים; אם נמשיך את שני החישובים על אותה מילה, או ששניהם יסתיימו בקבלה או ששניהם יסתיימו בדחיה (אבל זה ממש לא אומר שהחישובים יגיעו לאותם מצבים - ייתכן שלא יהיו להם מצבים משותפים בכלל). אינטואיטיבית זה אומר שאין לנו צורך בשני מצבים שונים עבור \( q,p \); אם החישוב מכאן והלאה הוא אותו הדבר, למה לא לאחד את שניהם למצב אחד?
בואו נחדד את מה שאני עושה. אגדיר יחס שקילות \( \equiv \) על \( Q \) באופן הבא: \( q\equiv p \) אם ורק אם \( L_{q}=L_{p} \). די קל לראות שזה יחס שקילות (כל יחס על קבוצה \( A \) שמוגדר באמצעות פונקציה \( f:A\to B \) כלשהי כך ש-\( a\equiv a^{\prime} \) אם ורק אם \( f\left(a\right)=f\left(a^{\prime}\right) \) הוא יחס שקילות). כעת אני טוען שקבוצת המנה \( Q/\equiv \) איזומורפית לקבוצת המנה \( \Sigma^{*}/R_{L} \), כאשר האיזומורפיזם נתון על ידי \( \left[w\right]_{R_{L}}\mapsto\left[q_{0}\cdot w\right]_{\equiv} \). להוכיח את זה - זה קצת סיפור. צריך להוכיח שהאיזומורפיזם הזה הוא באמת פונקציה; ושהיא חח”ע ועל.
כדי להוכיח שזו פונקציה צריך להוכיח שאין בהגדרה שלה תלות בנציג, כלומר שאם \( uR_{L}v \) אז \( q_{0}\cdot u\equiv q_{0}\cdot v \), כלומר ש-\( L_{q_{0}\cdot u}=L_{q_{0}\cdot v} \). נניח בשלילה שקיים \( z \) כך ש-\( z\in L_{q_{0}\cdot u} \) אבל \( z\notin L_{q_{0}\cdot v} \), אז \( \left(q_{0}\cdot u\right)\cdot z\in F \), כלומר \( uz\in L \), אבל \( vz\notin L \), בסתירה לכך ש-\( uR_{L}v \).
כדי להוכיח שהפונקציה היא חח”ע צריך להוכיח את הכיוון ההפוך - שאם \( L_{q_{0}\cdot u}=L_{q_{0}\cdot v} \) אז \( uR_{L}v \) - זה פשוט היפוך של הטיעון שנתתי קודם.
כדי להראות שהפונקציה היא על, ניקח מחלקת שקילות \( \left[q\right]_{\equiv} \) כלשהי. מכיוון שהנחתי שכל מצבי האוטומט ישיגים (בדיוק בשביל השלב הזה) הרי שקיים \( w \) כך ש-\( q=q_{0}\cdot w \), ולכן \( \left[w\right]_{R_{L}} \) הוא מקור של \( \left[q\right]_{\equiv} \), וסיימנו.
המסקנה היא שכדי לחשב את האוטומט המינימלי, מספיק לנו למצוא את מחלקות השקילות של \( \equiv \). אחרי שעשינו זאת, עדיין צריך להסביר מה יהיה המצב ההתחלתי שלנו, מי יהיו המצבים המקבלים ומה תהיה פונקציית המעברים. נלך על פי האיזומורפיזם שהצעתי: המצב ההתחלתי יהיה התמונה של \( \left[\varepsilon\right]_{R_{L}} \), כלומר \( \left[q_{0}\right]_{\equiv} \); התמונה של כל מצב מקבל \( \left[w\right]_{R_{L}} \) (כאשר \( w\in L \)) תהיה \( \left[q_{0}\cdot w\right]_{\equiv} \), ואנחנו יודעים ש-\( q_{0}\cdot w\in F \), כלומר המצבים המקבלים באוטומט שלנו יהיו מחלקות השקילות של מצבים מקבלים ב-\( Q \); ופונקציית המעברים תוגדר בתור \( \delta\left(\left[q\right]_{\equiv},\sigma\right)=\left[q\cdot\sigma\right]_{\equiv} \). זה נותן לנו את האוטומט האופטימלי של מייהיל-נרוד. כל מה שנשאר להסביר הוא איך מוצאים את מחלקות השקילות של \( \equiv \).
הדרך שבה אעשה זאת היא איטרטיבית - אני אתחיל מיחס שקילות שגוי, שהוא גס מדי - כלומר, כל מי שאמור להיות שקול אכן שקול, אבל יש גם איברים לא שקולים ב-\( \equiv \) שיהיו שקולים ביחס שלי. לאט לאט אני אלך ואעדן את היחס - כלומר, אם שני איברים לא היו שקולים, הם ימשיכו להיות כאלו, אבל בכל איטרציה אני אקח כמה איברים שהיו שקולים קודם ואפריד אותם זה מזה. נמשיך לבצע את זה עד שנגיע לאיטרציה שבה היחס לא השתנה, ואני אטען שאז הגעתי אל \( \equiv \). פורמלית, אבנה סדרה של יחסי שקילות \( \mathcal{Q}_{0},\mathcal{Q}_{1},\dots \) עד שאגיע למצב שבו \( \mathcal{Q}_{k}=\mathcal{Q}_{k+1} \), והטענה תהיה שאז \( \mathcal{Q}_{k} \) הוא בדיוק \( \equiv \), כלומר ש-\( q\mathcal{Q}_{k}p \) אם ורק אם \( L_{q}=L_{p} \).
הנה הצעה לגבי האופן שבו כדאי לאתחל:\( \mathcal{Q}_{0}=\left\{ Q\right\} \) (אני מתאר כאן את יחס השקילות בתור חלוקה של \( Q \)), כלומר כל האיברים יהיו שקולים זה לזה. מכאן והלאה אנחנו “מתקנים” כשאנחנו מוצאים דוגמאות נגדיות לכך שזוגות של מצבים הם שקולים. הדוגמה הנגדית הראשונה היא \( \varepsilon \). מן הסתם היא מפרידה בדיוק את אותם מצבים שהם מקבלים מאלו שאינם מקבלים (למה?) ולכן יותר הגיוני לאתחל \( \mathcal{Q}_{0}=\left\{ Q\backslash F,F\right\} \) במקום לאתחל עם קבוצה אחת. מכאן והלאה נפעל איטרטיבית: בהינתן \( \mathcal{Q}_{k} \) נחשב מתוכה את \( \mathcal{Q}_{k+1} \) שהיא קצת יותר מדוייקת מ-\( \mathcal{Q}_{k} \), עד שנגיע למצב שבו אין יותר שינויים.
עכשיו, בהינתן \( p,q \) שהם שקולים ב-\( \mathcal{Q}_{k} \), אני אבדוק אם קיים \( a \) כך ש-\( q\cdot a,p\cdot a \) לא שקולים ש-\( \mathcal{Q}_{k} \). אם קיים כזה, אני מפריד את \( p,q \) ב-\( \mathcal{Q}_{k+1} \). אם \( p,q \) היו שקולים ב-\( \mathcal{Q}_{k} \) ולא מצאתי \( a \) מפריד שכזה, אני ממשך לסמן אותם כשקולים. הניסוח המילולי הזה מסתיר מאחוריו סכנה כלשהי לסיטואציה לא מוגדרת היטב - שיהיו לי שלושה מצבים \( p,q,r \) כך ש-\( p,q \) אמורים להיות לא שקולים אבל \( p,r \) אמורים להיות שקולים וגם \( q,r \) אמורים להיות שקולים. אם זה מטריד אתכם קחו רגע כדי להוכיח שזה לא יכול לקרות, ולכן אנחנו מקבלים שגם \( \mathcal{Q}_{k+1} \) הוא יחס שקילות, וכזה שמעדן את \( \mathcal{Q}_{k} \). מכיוון שאלו יחס שקילות על קבוצה סופית וכל אחד מהם מעדן את קודמו, מתישהו בהכרח נגיע לנקודת שבת - \( \mathcal{Q}_{k}=\mathcal{Q}_{k+1} \), מה שמוכיח שהאלגוריתם תמיד מסתיים. נותר להוכיח שהתוצאה היא אכן יחס השקילות שאנחנו רוצים.
כיוון אחד קל. נוכיח באינדוקציה על \( t \) שאם עבור זוג מצבים כלשהו \( p,q \) מתקיים ש-\( L_{p}=L_{q} \) אז \( q\mathcal{Q}_{t}p \). עבור \( t=0 \) זה בבירור עובד, כי אם \( q \) לא שקול ל-\( p \) ב-\( \mathcal{Q}_{0} \) אז בלי הגבלת הכלליות \( p\in F \) ו-\( q\notin F \), מה שאומר ש-\( \varepsilon\in L_{p} \) אבל \( \varepsilon\notin L_{q} \). כעת, נניח שזה עובד עבור \( t \) ונוכיח ל-\( t+1 \): אם \( L_{p}=L_{q} \) אבל \( p,q \) לא שקולים ב-\( \mathcal{Q}_{t+1} \). הנחת האינדוקציה שלנו אומרת ש-\( p,q \) כן היו שקולים ב-\( \mathcal{Q}_{t} \), ולכן על פי אופן פעולת האלגוריתם, זה אומר שקיים \( a \) כך ש-\( p\cdot a \) ו-\( q\cdot a \) לא שקולים ב-\( \mathcal{Q}_{t} \); מכאן שבהכרח \( L_{q\cdot a}\ne L_{p\cdot a} \) (למה?). בלי הגבלת הכלליות נובע מכך שקיים \( z \) כך ש-\( z\in L_{q\cdot a} \) אבל \( z\notin L_{p\cdot a} \) - מכאן נובע ש-\( az\in L_{q} \) אבל \( az\notin L_{p} \), בסתירה לכך ש-\( L_{q}=L_{p} \), מה שמסיים את הכיוון הזה.
בכיוון השני, אני רוצה להוכיח שאם \( p\mathcal{Q}_{k}q \) אז \( L_{p}=L_{q} \). נניח שזה לא המצב, אז תהיה לי לפחות דוגמה נגדית אחת. דוגמה נגדית מורכבת משלושה דברים: זוג מצבים \( p,q \) כך ש-\( p\mathcal{Q}_{k}q \), וכמו כן מילה \( z \) כך ש-\( z\in L_{p} \) אבל \( z\notin L_{q} \). כדי שההוכחה תעבוד, אני לא סתם אסתכל על דוגמה נגדית אקראית, אלא אקח כזו שבה \( z \) הוא הקצר ביותר האפשרי - כלומר, שכל מילה קצרה יותר מ-\( z \) לא מופיעה באף דוגמה נגדית.
עכשיו אפשר לפרק את \( z \) באופן הבא: \( z=az^{\prime} \) (אני מניח ש-\( z \) הוא מאורך לפחות 1 - למה זה אפשרי?). נקבל ש-\( z^{\prime}\in L_{p\cdot a} \) אבל \( z^{\prime}\notin L_{q\cdot a} \). אני חותר לכך שזו סתירה למינימליות של האורך של \( z \); לצורך כך צריך להשתכנע שהשלשה \( p\cdot a,q\cdot a \)ו-\( z^{\prime} \) גם היא דוגמה נגדית, כלומר ש-\( p\cdot a\mathcal{Q}_{k}q\cdot a \). הסיבה שזה נכון היא שאם לא היה מתקיים ש-\( p\cdot a\mathcal{Q}_{k}q\cdot a \) אז האלגוריתם שלנו היה מפריד את \( p,q \) ב-\( \mathcal{Q}_{k+1} \) ובוודאי שלא היינו מקבלים \( \mathcal{Q}_{k}=\mathcal{Q}_{k+1} \). זה מסיים את הוכחת הנכונות של האלגוריתם. עכשיו לכו לתכנת אותו!
חזרתם? יופי. בואו נעבור לחלק המוזר של הפוסט - עוד אלגוריתם מינימזציה שלא ברור בכלל מאיפה הוא הגיע ולמה הוא עובד.
כדי שנוכל לתאר את האלגוריתם בצורה פשוטה, כמה סימונים חדשים. נסמן ב-\( A \) אוטומט סופי כלשהו (לאו דווקא דטרמיניסטי, אבל בלי מסעי-\( \varepsilon \)). נסמן ב-\( A_{\mbox{det}} \) את הדטרמיניזציה של \( A \) - האוטומט שמתקבל מאוטומט החזקה של \( A \) על ידי הסרת מצבים לא ישיגים (אסביר את זה בפירוט בהמשך). נסמן ב-\( A^{R} \) את ההיפוך של \( A \) - אוטומט שמתקבל מ-\( A \) על ידי היפוך כל כיווני הקשתות והחלפת תפקידי המצבים ההתחלתיים והמקבלים (כזכור, \( L\left(A^{R}\right)=\left(L\left(A\right)\right)^{R} \) כאשר \( L^{R} \) היא היפוך כל המילים ב-\( L \)), ונסמן ב-\( A_{\mbox{min}} \) את האוטומט הדטרמיניסטי המינימלי ששקול ל-\( A \). אז אני טוען שמתקיים:
\( A_{\mbox{min}}=\left(\left(\left(A^{R}\right)_{\mbox{det}}\right)^{R}\right)_{\mbox{det}} \)
במילים: כדי לקבל את האוטומט הדטרמיניסטי המינימלי ששקול ל-\( A \), פעלו כך: קודם כל הפכו את \( A \). בצעו דטרמיניזציה לתוצאה. הפכו את התוצאה ובצעו למה שקיבלתם דטרמיניזציה. הופס! קיבלתם את האוטומט המינימלי.
לא יודע מה אתכם, אני עדיין מרגיש שמשהו מאוד מוזר הולך פה גם בזמן שבו אני כותב את השורות הללו. בתקווה עד שאסיים לכתוב את הפוסט תהיה לכולנו אינטואיציה יותר טובה למה זה עובד, ולא סתם הוכחה פורמלית.
סיבה עיקרית לקושי שאני מרגיש ללא ספק נובעת מכך שאני רגיל לחשוב על דטרמיניזציה של אוטומט בתור משהו ש”מנפח” אותו, ולכן לא ייתכן ששתי דטרמיניזציות יקטינו את מספר המצבים ויתנו לנו אוטומט מינימלי. לכן חשוב להסביר מה זו בעצם הדטרמיניזציה הזו. בפוסט על אוטומט אי דטרמיניסטי הצגתי את ההוכחה שקיים לו אוטומט דטרמיניסטי שקול - מה שנקרא אוטומט חזקה. כל מצב של אוטומט החזקה הוא קבוצה של מצבים של האוטומט המקורי - אחרי קריאת \( w \) אנחנו מגיעים לקבוצת כל המצבים שיש ריצה על \( w \) באוטומט המקורי שמביאה אותו אליהם.
באופן הזה, הרבה פעמים אנחנו מקבלים מצבים מיותרים. דוגמה טריוויאלית היא מה שנקבל אם נבצע את הבניה הזו על אוטומט שהוא כבר דטרמיניסטי, המצבים היחידים שנזדקק להם בפועל הם קבוצות שהן סינגלטונים (למה?). כל שאר המצבים פשוט יהיו לא ישיגים מהמצב ההתחלתי. אז כשרוצים לבצע דטרמיניזציה בפועל של אוטומט, לא מתחילים מבניה של כל המצבים האפשריים (יש המון כאלו - 2 בחזקת מספר המצבים של האוטומט המקורי). פשוט מבצעים DFS מהמצב ההתחלתי, שהוא \( \left\{ q_{0}\right\} \). לכל אות מחשבים לאיזה מצב של אוטומט החזקה עוברים ממנו, ולכל מצב כזה מבצעים את אותו חישוב, וכדומה. התוצאה עשויה להיות אוטומט החזקה המלא, במקרה שבו כל המצבים שלו הם ישיגים; אבל לרוב היא תהיה הרבה יותר קטנה ולכן העניין הזה פרקטי בפועל. כאמור, אם \( A \) הוא אוטומט, אז אסמן ב-\( A_{\mbox{det}} \) את הדטרמיניזציה הזו שלו.
כדי לקבל אינטואיציה כלשהי לכך שזה עובד, בואו נראה דוגמת צעצוע. אני אקח אוטומט עבור שפת כל המילים מאורך אי-זוגי מעל \( \left\{ a,b\right\} \) ובכוונה האוטומט הזה יהיה לא מינימלי - במקום שני מצבים יהיו לו שלושה, כשבבירור אפשר לאחד את המצב הראשון והשלישי:

הדבר הראשון שנעשה יהיה היפוך של האוטומט הזה. אני הופך את כיווני הקשתות, הופך כל מצב התחלתי למקבל, וכל מצב מקבל להתחלתי. כאן יש רק מצב מקבל אחד אז אני לא מקבל תופעה מוזרה של אוטומט עם כמה מצבים התחלתיים (כבר ראינו שאוטומט כזה הוא לגיטימי ושקול למודל הדטרמיניסטי):
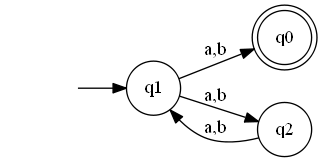
ועכשיו אני מבצע דטרמיניזציה:
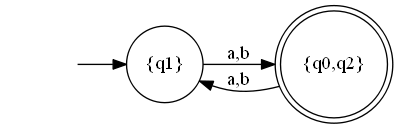 הופס! קיבלנו רק שני מצבים במקום שלושה - איכשהו הדטרמיניזציה זיהתה ש-\( q_{0},q_{2} \) הם אותו הדבר מבחינתנו והם נדחסו למצב יחיד. למעשה, מה שקיבלנו הוא כבר אוטומט עבור השפה שלנו - לא צריך את ההיפוך והדטרמיניזציה הנוספים, והם גם לא משנים את האוטומט כלל (למה?).
הופס! קיבלנו רק שני מצבים במקום שלושה - איכשהו הדטרמיניזציה זיהתה ש-\( q_{0},q_{2} \) הם אותו הדבר מבחינתנו והם נדחסו למצב יחיד. למעשה, מה שקיבלנו הוא כבר אוטומט עבור השפה שלנו - לא צריך את ההיפוך והדטרמיניזציה הנוספים, והם גם לא משנים את האוטומט כלל (למה?).
כדי להבין למה כאן הספיק לנו רק “חצי” מהאלגוריתם, הנה המשפט הכללי שעליו אני מסתמך באלגוריתם. לפני כן, הגדרה אחרונה: נאמר שאוטומט \( A \) הוא קו-בלהבלה, כאשר במקום “בלהבלה” קחו את התכונה החביבה עליכם, אם \( A^{R} \) מקיים את בלהבלה. למשל, \( A \) הוא קו-דטרמיניסטי אם \( A^{R} \) הוא דטרמיניסטי; והוא קו-נגיש אם \( A^{R} \) נגיש, כלומר כל מצבי \( A^{R} \) ישיגים. הנה המשפט: אם \( A \) הוא קו-דטרמיניסטי וקו-נגיש, אז \( A_{\mbox{min}}=A_{\mbox{det}} \). מכאן יותר קל להבין מה קרה בנוסחה \( A_{\mbox{min}}=\left(\left(\left(A^{R}\right)_{\mbox{det}}\right)^{R}\right)_{\mbox{det}} \): החלק הפנימי, \( \left(\left(A^{R}\right)_{\mbox{det}}\right)^{R} \), הוא פשוט מה שצריך לעשות כדי לקבל מ-\( A \) שהתחלנו ממנו אוטומט שקול שהוא קו-דטרמיניסטי וקו-נגיש (שתי התכונות הללו מושגות בו זמנית על ידי ביצוע דטרמיניזציה). בדוגמת הצעצוע שנתתי, \( A \) שלי לא היה קו-דטרמיניסטי, אבל מה שכן היה נכון הוא ש-\( A^{R} \) קיבל את אותה שפה כמו \( A \) (כי מילה היא מאורך אי זוגי אם ורק אם ההיפוך שלה כזה), ואותו \( A^{R} \) דווקא כן מקיים את התכונה שהוא קו-דטרמיניסטי וקו-נגיש (כי \( A \) היה דטרמיניסטי ונגיש). לכן כשביצענו את הדטרמיניזציה של \( A^{R} \) קיבלנו אוטומט מינימלי עבור השפה של \( A^{R} \), ובמקרה שלנו זו הייתה השפה שאנחנו מחפשים.
אז הקסם הוא בכך שדטרמיניזציה של אוטומט עשויה, בתנאים נחמדים מסויימים, לבנות ממנו את האוטומט המינימלי. זה לא באמת מופרך, אם חושבים על זה לרגע. דטרמיניזציה בונה אוטומט חדש, שמצביו הם קבוצות של מצבים של האוטומט המקורי - זה בדיוק גם מה שעשינו באלגוריתם הקודם שהצגנו. אבל הסיטואציה בכל זאת שונה - הקבוצות שנקבל לא יהיו מחלקות השקילות של היחס \( \equiv \) (למשל, בדוגמה שלי, \( q_{0} \) מתקבץ יחד עם \( q_{2} \) למרות שאחד הוא מצב מקבל והשני איננו). יש בעיה מהותית לדבר בכלל על היחס \( \equiv \) כי הוא הוגדר עבור אוטומטים דטרמיניסטיים, אבל \( A \) שלנו עשוי להיות אי-דטרמיניסטי. לכן בואו נחזור לתיאור האוטומט המינימלי שנתתי בתחילת הפוסט - מצבי האוטומט הם השפות \( u^{-1}L \). כלומר, אני אראה התאמה חח”ע ועל בין מצבי \( A_{\mbox{det}} \) ובין השפות \( u^{-1}L \). האינטואיציה ברורה - לכל \( u\in\Sigma^{*} \), נעביר את המצב שאליו מגיעים על ידי קריאת \( u \) ב-\( A_{\mbox{det}} \) אל \( u^{-1}L \) (דהיינו, אם \( S=\hat{\delta}\left(q_{0},u\right) \), אז מבצעים \( S\mapsto u^{-1}L \)). כדי להיווכח בכך שההתאמה הזו היא בכלל פונקציה ושהיא חח”ע צריך להראות שלכל זוג מילים \( u,v \) מתקיים ש-\( \hat{\delta}\left(q_{0},u\right)=\hat{\delta}\left(q_{0},v\right) \) אם ורק אם \( u^{-1}L=v^{-1}L \) - אנחנו מקבלים את אותו הפלט. מרגע שהראיתי את זה, סיימתי, כי ההתאמה היא בבירור על (הרי התחלנו עם \( u\in\Sigma^{*} \) כלשהי, זה מבטיח שנוכל לכסות את כל ה-\( u^{-1}L \)-ים)
בכיוון אחד, אם \( \hat{\delta}\left(q_{0},u\right)=\hat{\delta}\left(q_{0},v\right) \) אז מן הסתם לכל הרחבה של החישוב באמצעות \( z \), אם יהיה חישוב מקבל באחד האוטומטים יהיה גם בשני. לכן \( uz\in L\iff vz\in L \) מה שמראה ש-\( u^{-1}L=v^{-1}L \). הכיוון המעניין הוא השני: אנו מניחים ש-\( u^{-1}L=v^{-1}L \) וצריכים להראות שהמצבים שאליהם \( A \) יכול להגיע על ידי קריאת \( u \) הם בדיוק המצבים שאליהם \( A \) יכול להגיע על ידי קריאת \( v \). כאן מן הסתם ייכנסו לפעולה התכונות שמאפיינות את \( A^{R} \).
בואו ניקח \( p \) כך שקיימת ריצה של \( A \) על \( u \) שמסתיימת ב-\( p \). האבחנה הראשונה שלנו היא שאפשר להמשיך את הריצה הזו ולהגיע למצב מקבל; זה נובע מכך ש-\( A^{R} \) הוא אוטומט ישיג, ולכן \( p \) ישיג ממצב התחלתי של \( A^{R} \) - כלומר, ב-\( A \) העסק מתהפך ואנחנו מקבלים שיש מצב מקבל של \( A \) שישיג מ-\( p \). כלומר, קיים \( z \) כך ש-\( uz\in L \), דהיינו \( z\in u^{-1}L=v^{-1}L \), ולכן גם \( vz\in L \). כלומר: קיימת ריצה של \( A \) על \( vz \) שמסתיימת במצב מקבל. עכשיו נכניס לתמונה את העובדה ש-\( A^{R} \) הוא דטרמיניסטי; בפרט זה אומר שקיים לו מצב התחלתי יחיד ולכן ל-\( A \) יש מצב מקבל יחיד, כלומר הריצה של \( A \) על \( vz \) מסתיימת באותו מצב כמו הריצה של \( A \) על \( uz \). בואו נסמן ב-\( p^{\prime} \) את המצב שאליו הריצה הזו מגיעה אחרי סיום קריאת \( v \).
מה למדנו? שב-\( A \) קיימים שני מצבים, \( p,p^{\prime} \), שעל ידי קריאת \( z \) ניתן לעבור מכל אחד מהם אל המצב המקבל היחיד של \( A \). זה אומר שב-\( A^{R} \), על ידי קריאת \( z^{R} \), אפשר להגיע גם ל-\( p \) וגם ל-\( p^{\prime} \). אבל הרי \( A^{R} \) הוא דטרמיניסטי, ולכן זה אפשרי רק אם \( p=p^{\prime} \). המסקנה: קיימת ריצה של \( A \) על \( v \) שמסתיימת ב-\( p \), ולכן \( \hat{\delta}\left(q_{0},u\right)\subseteq\hat{\delta}\left(q_{0},v\right) \). ההוכחה בכיוון השני זהה, וקיבלנו שהאיזומורפיזם שהגדרתי בין מצבי \( A_{\mbox{det}} \) ובין השפות \( u^{-1}L \) עובד. עדיין צריך להשתכנע ש-\( A_{\mbox{det}} \) זהה לאוטומט שבונים מתוך \( u^{-1}L \), אבל קל למדי לוודא את זה. סיימנו את הבניה הזו!
כמובן, נשאלת השאלה איזה מבין שני האלגוריתמים הוא עדיף. בשניהם זמן הריצה עשוי להיות אקספוננציאלי במספר המצבים (נסו למצוא דוגמאות נגדיות!) ולכן אין לי תשובה טובה - כנראה שכדאי לנסות להריץ אחד, ואם לא עובד מהר, לנסות את השני. יש גם שאלה של מה בעצם הקלט שלנו - אם נתון לנו אוטומט דטרמיניסטי, כנראה עדיף להפעיל את האלגוריתם הראשון; אם נתון אוטומט אי-דטרמיניסטי, אז כדי להפעיל את האלגוריתם הראשון ממילא יהיה צורך לבצע דטרמיניזציה, אז אפשר כבר לנסות ולהפעיל את האלגוריתם השני (ולבדוק אם יש לנו מזל והוא קו-נגיש וקו-דטרמיניסטי מראש). אבל אם אם זמן הריצה של האלגוריתם השני היה נחות מזה של הראשון זה לא היה כל כך אכפת לי - פשוט כי זה כל כך מגניב.
נהניתם? התעניינתם? אם תרצו, אתם מוזמנים לתת טיפ: