האובייקט המרכזי שאיתו מתעסקים מחשבים הוא מספרים טבעיים. ברמה הבסיסית ביותר שלו, מחשב יודע לעשות פעולות רק על אפסים ואחדים - ביטים - והפעולות הללו הן פעולות אריתמטיות בסיסיות של חיבור וכפל (ופעולות לוגיות אבל נעזוב את זה). עם זאת, סוג הנתונים הנפוץ ביותר עבור המשתמשים בתוכנה איננו מספרים אלא טקסט כתוב - סדרה של תווים. ליצור הזה קוראים במדעי המחשב "מחרוזת".
הדרך שבה מייצגים מחרוזות במחשב היא גם כן באמצעות מספרים - לכל אות יש מספר מזהה משלה, ומחרוזת היא פשוט סדרה ("מערך") של מספרים מזהים שכאלו. קרוב לודאי ששמעתם על קוד ASCII - זו הדוגמה הקלאסית לקוד שבו מיוצגים תווים באמצעות מספרים. כך למשל התו "a" מיוצג על ידי המספר 97, והתו "4" מיוצג על ידי המספר 52. העובדה שמדובר בתווים ולא במספרים באה לידי ביטוי רק כשהם נכתבים על המסך - ואז משתמשים בכלי כלשהו שיודע לתרגם את המספר לציור על המסך (ישנן דרכים רבות לצייר את התו המיוצג על ידי מספר כלשהו על המסך - המושג של "גופן" מתאר חלק מהשוני האפשרי בין שיטות ציור שונות).
למה זה חשוב? כדי לשכנע אתכם שאפשר להתנתק מהייצוג הגשמי שלהן ולחשוב על מחרוזות ועל תווים בתור אובייקטים לגיטימיים עם חיים משל עצמם - ולכן גם מבני נתונים המוקדשים להם. מבנה נתונים אחד שכזה, שאולי אינו בהכרח היעיל ביותר למטרות שאציג (יש יתרונות וחסרונות ואיני בקיא בכולם) הוא עץ הסיומות שהזכרתי בפוסט הקודם. מכיוון שהוא מקרה פרטי של עץ כללי שמשמש לאחסון מחרוזות הנקרא Trie, אציג קודם את ה-Trie.
הרעיון פשוט למדי - נניח שנתונות לנו כמה מחרוזות ואנו רוצים לאחסן אותן בצורה שתחסוך לנו מקום. לפני שנשלוף את כלי הדחיסה הכבדים שלנו, אפשר לחשוב על ניצול העובדה שחלק מהמחרוזות עשויות להיות בעל חלק התחלתי משותף. לחלק התחלתי של מחרוזת - כלומר, סדרה רציפה של תווים מתחילתה נהוג לקרוא "רישא" (מלשון ראש) ולחלק בסוף של מחרוזת קוראים "סיפא". כך למשל במחרוזת "אנציקלופדיה" חלק מהרישות הן "א", "אנצ" ו-"אנציקלופדיה", ואילו חלק מהסיפות הן "ה", "פדיה", ו-"אנציקלופדיה".
הנה דוגמה ל-Trie שאליו הוכנסו המילים הבאות: "Math\(", "Suffix\)", "Suffer\(", "Journeyman\)", "Journal\(", "Journey\)". הדולר בסוף כל מילה הוא חלק סטנדרטי מכל Trie - זה סימון מוסכם ל"כאן נגמרת מילה". בלי זה, היה קשה להבחין שהעץ מכיל גם את "Journey" וגם את "Journeyman":
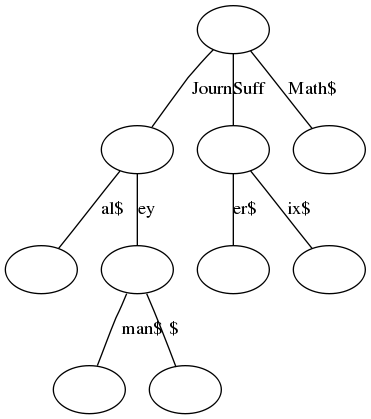
ממבט ראשון זה נראה מבלבל למדי. הרעיון הוא שכל צומת מייצג רישא של מילה כלשהי שמאוחסנת בעץ, כשהשורש מייצג את הרישא ה"ריקה", שאינה מכילה אף אות. כל צומת מסומנת על ידי אות אחת או יותר, ומתארת את ההבדל בין שתי הרישות שהיא מחברת - למשל, הקשת שמסומנת ב-"Suff" פירושה שהרישא שמייצגת הצומת התחתונה יותר היא הרישא שמייצגת הצומת העליונה, ועוד המחרוזת "Suff" לאחר מכן. כפי שאפשר לראות, הרישא "Suff" בעצמה היא בעלת שני בנים אפשריים - גם המילה "\(Suffer" וגם המילה "\)Suffix" מתחילות בה.
אם כן, זהו Trie. יש לו שימושים בפני עצמו, אבל אני רוצה להגיע בזריזות לסוג ה-Trie שמעניין אותי - עץ סיומות, Suffix Tree (ובשם אחר - "עץ סיפות", מהמילה סיפא). מרגע שברור מהו Trie לא קשה להבין מהו עץ סיומות - זהו Trie שהמחרוזות שהוא מכיל הן בדיוק כל הסיומות של מילה כלשהי. דוגמה נפוצה היא עץ סיומות עבור המילה "\(banana" - עץ שנראה כך:
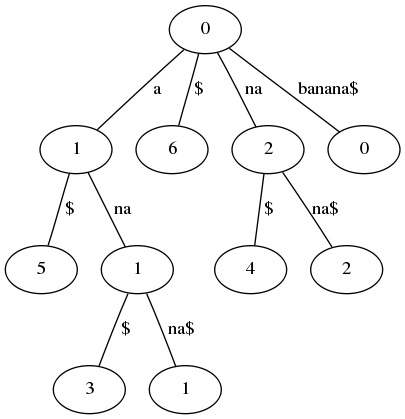 יש הבדל בולט בין העץ הזה ובין Trie סטנדרטי - בצמתים עכשיו כתוב מספר. עבור עלה (צומת ללא בנים) המספר מציין את המיקום במילה שבו מתחילה הסיפא שמיוצגת על ידי העלה. כן. זה היה מבלבל. מאוד. בואו ננסה שוב, על ידי דוגמה.
נתחיל מהשורש. נלך לבן השמאלי ביותר - הוא מייצג את הרישא "a" שמשותפת לכמה וכמה סיומות. נלך ממנו שוב לבן השמאלי ביותר, ונגיע לצומת שמייצג את "\)a", כלומר, את אחת מהסיומות של המילה (הסיומת שמורכבת משתי האותיות האחרונות בה - זכרו שאני מחשיב גם את \( בתור אות). כעת, מה המקום במילה \)banana שממנו מתחילה הסיומת "\(a"? התשובה היא באיזו שפת תכנות אתם עובדים. בשפות תכנות רבות נהוג להתחיל את הספירה של אותיות המחרוזות מאפס ולא מאחד. הסיבות הן בעיקרן של נוחיות, ולא אכנס כרגע להסביר על למה שיטת סימון תמוהה שכזו היא נוחה יותר - זה עניין לפוסט נפרד. העיקר כרגע הוא שאם סופרים את אותיות המחרוזת החל מ-0, הרי שהאות a שבה מתחילה הסיומת \)a היא האות החמישית, ואכן בצומת מאוחסן המספר 5.
יש הבדל בולט בין העץ הזה ובין Trie סטנדרטי - בצמתים עכשיו כתוב מספר. עבור עלה (צומת ללא בנים) המספר מציין את המיקום במילה שבו מתחילה הסיפא שמיוצגת על ידי העלה. כן. זה היה מבלבל. מאוד. בואו ננסה שוב, על ידי דוגמה.
נתחיל מהשורש. נלך לבן השמאלי ביותר - הוא מייצג את הרישא "a" שמשותפת לכמה וכמה סיומות. נלך ממנו שוב לבן השמאלי ביותר, ונגיע לצומת שמייצג את "\)a", כלומר, את אחת מהסיומות של המילה (הסיומת שמורכבת משתי האותיות האחרונות בה - זכרו שאני מחשיב גם את \( בתור אות). כעת, מה המקום במילה \)banana שממנו מתחילה הסיומת "\(a"? התשובה היא באיזו שפת תכנות אתם עובדים. בשפות תכנות רבות נהוג להתחיל את הספירה של אותיות המחרוזות מאפס ולא מאחד. הסיבות הן בעיקרן של נוחיות, ולא אכנס כרגע להסביר על למה שיטת סימון תמוהה שכזו היא נוחה יותר - זה עניין לפוסט נפרד. העיקר כרגע הוא שאם סופרים את אותיות המחרוזת החל מ-0, הרי שהאות a שבה מתחילה הסיומת \)a היא האות החמישית, ואכן בצומת מאוחסן המספר 5.
כאשר מדובר על צמתים שאינם עלים, המספר שמאוחסן בהם הוא המינימום מבין המספרים של הבנים. הסיבה לכל המספור הזה תובהר בהמשך, שבו יש להתייחס לשתי שאלות מהותיות:
- איך אפשר, בהינתן מחרוזת, לבנות ממנה עץ סיומות?
- בשביל מה זה טוב?
לשאלה 1 יש תשובה פשוטה ותשובה מסובכת. התשובה הפשוטה היא "עבור על כל הסיומות של המחרוזת והוסף את כולם ל-Trie", מה שמצמצם את שאלת בניית עץ הסיומות לשאלת בניית Trie סטנדרטי. בנייה של יצור שכזה היא פשוטה מאוד מבחינה רעיונית - פשוט "מטיילים" על העץ עם האותיות של המילה שכעת מכניסים אליו עד שמגיעים לצומת שבו אין יציאה שמתאימה לנו, ואז מוסיפים צומת חדש. קל לומר וקשה לעשות - מבחינה תכנותית בניית העץ יכולה להיות מעצבנת למדי מבחינה טכנית, ולא אכנס לכל השיקולים התכנותיים; למרות זאת, בניית עץ שכזה בשפת תכנות חזקה (למשל Ruby) לא דורשת יותר מכמה עשרות שורות קוד.
עם זאת, לשיטה הנאיבית הזו לבניית עץ סיומות יש חסרון פשוט - סיבוכיות זמן הריצה שלה, שהיא ריבועית בגודל המחרוזת (כי האורך הכולל של כל הסיומות האפשריות של מחרוזת הוא ריבועי בגודל המחרוזת - נסו להבין למה. הנה רמז). לכן הגילוי לפיו ניתן לבנות עץ סיומות למחרוזת בזמן שהוא לינארי באורך המחרוזת היה לא טריוויאלי בכלל, ומדובר בתוצאה נאה שלא אכנס אליה כאן.
בשלב הזה אתם עשויים לתהות - ריבועי שמירבועי, למי אכפת? הרי מילים הן בסך הכל יצורים די קצרים, אז מה כבר יכול להיות ההבדל?
הנקודה היא שמחרוזת איננה רק מילה, אלא כל אוסף של תווים, והרבה פעמים מעניינים אותנו אוספי תווים שהם ארוכים מאוד. למשל, המחרוזת יכולה להיות טקסט של ספר שלם, וספרים עשויים להכיל מאות אלפי תווים אם לא למעלה מכך. שימוש נפוץ אחר למחרוזות, אחד מהבסיסיים שבתחום הביולוגיה החישובית, הוא לייצוג DNA (למשל) - הרי ניתן לחשוב על DNA בתור מחרוזת ארוכה מאוד של ארבעה תווים (G,A,C,T). אין לי ידע קונקרטי לגבי האורכים ה"סטנדרטיים" של מחרוזות שעשויות לצוץ בשימוש הזה, אך למיטב הבנתי הוא עשוי להיות בקלות מסדר גודל של מיליוני תווים.
אבל מה כבר רוצים לעשות עם מחרוזות בגודל שכזה? המון דברים, והפשוט שבהם הוא מציאת תת מחרוזת. למשל, רוצים לחפש מילה או ציטוט מסויים בתוך ספר, או למצוא גן מסויים בתוך כרומוזום. קיימות כמה שיטות מחוכמות לביצוע החיפוש הזה שדורשות רק את הטקסט ה"נא" שבתוכו מחפשים ואת המחרוזת שמחפשים, ופועלות בזמן שלינארי באורך המחרוזת שבה מתבצע החיפוש (נסו להבין מדוע זה לא טריוויאלי, ומדוע זה הכרחי שזה יהיה המינימום). למעשה, חלק מהשיטות מגדילות לעשות ובמקרים רבים (בפרט, ככל שהמחרוזת אותה מחפשים גדולה יותר) מצליחות להמנע מלקרוא את כל הטקסט שבתוכו מתבצע החיפוש - נסו לחשוב כיצד נוצרת סיטואציה שבה ידוע שאפשר "להתעלם" בשלווה מחלק מהטקסט.
כעת נחשוב על סיטואציה שונה - נותנים לנו את הטקסט אבל טרם נותנים לנו משהו לחפש בתוכו. במקום זה אומרים "אתם יכולים לבצע עיבוד מקדים על הטקסט. אנחנו נלך לישון. נבוא מחר בבוקר ונפציץ בהמון שאלות שצריך לענות לכולן ממש מהר". העיבוד המקדים יהיה בניית עץ הסיומות (מכיוון שניתן לבנות אותו בזמן לינארי, אין מדובר בעבודה קשה מהותית מהעבודה שמשקיעים בחיפוש בודד - אם כי, כמובן, בפועל חיפוש בודד יהיה מהיר יותר, ובוודאי שלא ידרוש את כמות הזכרון הגדולה שאחסון עץ סיומות דורש). מרגע שעץ הסיומות קיים, ניתן למצוא כל מחרוזת בטקסט בזמן שלינארי באורך המחרוזת שאותה מחפשים, ובכמות המופעים שלה בטקסט. בפרט, זמן החיפוש לא תלוי בכלל באורך הטקסט שבתוכו מחפשים - אפילו אם הוא מאורך של מיליארדי תווים. לטעמי מדובר בתוצאה מדהימה למדי. כמובן שמסתתר מאחוריה משהו מסובך - עץ סיומות דורש, כאמור, הרבה מקום בזיכרון - אבל הכוח שהוא מספק הוא אדיר. והשימוש הזה הוא רק קצה הקרחון לכל הדברים שניתן לבצע בעזרת עץ סיומות.
אם כן, איך עושים את זה? התשובה פשוטה עד כדי גיחוך. נקרא למחרוזת שאותה מחפשים S. ראשית, מטיילים בעץ החל מהשורש תוך נסיון לקריאת S. אם הצלחנו לקרוא אותה - כלומר, הקשתות שעל פניהן עברנו בדרך הרכיבו את S (ואולי מחרוזת יותר ארוכה ש-S היא רישא שלה), נתבונן בצומת שאליו הגענו ונסמנו V. הוא מייצג את המחרוזת שקראנו עד כה - מחרוזת שמתחילה כאמור ב-S. אם נטייל ממנו עד לעלה כלשהו, נקרא סיפא של המילה שמתחילה ב-S - ובעלה, כזכור, שמור המיקום שבו הסיפא הזו מתחילה - כלומר, בדיוק המיקום שבו המופע הזה של S מתחיל. כל עלה שאליו נטייל מ-V ייתן לנו מופע נוסף ואחר של S.
זה מבלבל למדי, ולכן נחזור שוב לדוגמת הבננה. נניח שאנו מחפשים את המחרוזת "na". אנו מתחילים את החיפוש משורש העץ ומתבוננים בקשתות. מייד אנו רואים קשת שמתאימה למחרוזת שאנו מחפשים - מכילה na - ולכן אנחנו מתקדמים עליה ומגיעים לצומת חדש, שמסמל את "החלק הראשון של כל הסיומות ששמורות בעץ ומתחילות במחרוזת na". כעת אנו מתקדמים לשני הצמתים הבנים, שהם עלים ולכן כל אחד מהם מייצג סיומת שלמה - בראשון כתוב 2 ובשני 4, ולכן 2 ו-4 הם המקומות שבהם מתחילות הסיומות שהם מייצגים.
במקום 2 נמצאת הסיומת "\(nana" ובמקום 4 נמצאת הסיומת "\)na". שתי הסיומות הללו מתחילות ב-na, ואלו שני מופעים שונים של na, כך שלא ביצענו "עבודה כפולה".
עוד דוגמה: נניח שאנו מחפשים את "ana". המחרוזת הזו מופיעה בתור ההתחלה של סיומת גם כן פעמיים - פעם של הסיומת "\(anana\), ופעם של הסיומת "$ana". שתי הסיומות הללו נמצאות, כמובן, בעץ (הרי הוא הוגדר להכיל את כל הסיומות) ושתיהן מתחילות ב-ana כך שקל לאתרן על ידי טיול שאורכו כאורך ana לכל היותר. הפעם הטיול הוא בן שני צעדים - קודם קוראים את "a" ורק לאחר מכן את "na", אך העיקרון זהה.
שאלה אחרונה שעשויה לצוץ היא מדוע לאחר שכבר נקראה המילה שאותה מחפשים, ונותר לטייל בכל תת העץ שמצאנו ולדווח את המספר ששמור בכל אחד מהעלים, הסיבוכיות של שלב החיפוש הזה אינה תלויה בגודל העץ או דבר מה דומה. הנימוק לכך שהסיבוכיות היא לינארית במספר המופעים של המחרוזת שאנו מחפשים הוא מחוכם מעט: באופן כללי, כשיש לנו עץ שבו לכל צומת שאינו עלה יש שני בנים לפחות אז מספר הצמתים הכולל בו הוא לינארי במספר העלים שלו. בעץ סיומת עניין שני הבנים בהכרח מתקיים, כמעט על פי הגדרה - אחד מהשלבים הטכניים בבניית עץ כזה היא "דחיסה" של צמתים עם בן יחיד לצומת בודד, על ידי הגדלת המחרוזת שנמצאת על הקשת שמובילה אל הצומת.
ההוכחה של הטענה שלעיל פשוטה למדי; הנה הוכחה לא פורמלית אבל די משכנעת לטעמי. נתחיל משורש בודד ונבנה אט אט את העץ. כל צעד בבנייה כרוך בלקיחה של צומת שעד עתה לא היו לו בנים (כלומר, היה עלה) והוספת הבנים שלו (מבלי להוסיף להם בנים - עדיין). מה קורה בכל צעד? מספר העלים קטן ב-1 (כי לקחנו צומת שהיה עלה והוספנו לו בנים) אבל גדל ב-2 לפחות (כי הוספנו שני בנים לפחות). מספר הצמתים הכולל בעץ גדל ב-2. על כן, על כל שני צמתים שמוסיפים לעץ, מוסיפים לפחות עלה אחד לסכום העלים הכולל, ולכן לפחות מחצית מהצמתים בעץ יהיו עלים.
כעת, מספר העלים בתת העץ שבו מטיילים בשלב השני של החיפוש הוא בדיוק מספר המופעים של המחרוזת שמחפשים בתוך הטקסט, שכן כל עלה נותן לנו מופע אחר שלה - לכן טיול בכל תת העץ, שסיבוכיות הזמן שלו לינארית במספר צמתי תת העץ, הוא בסיבוכיות זמן שלינארית במספר המופעים של המחרוזת שמחפשים.
זהו השימוש ה"קלאסי" של עץ סיומות; יש עוד רשימה ארוכה ומעניינת של דברים שניתן לעשות בעזרתו (למשל, מציאת תת מחרוזת שמשותפת לשתי מחרוזות; מציאת מחרוזת ש"כמעט" מתאימה למחרוזת שמחפשים, פרט לטעות אחת, וכו'), אבל השימוש הבא שאני רוצה לתאר לא נוגע באופן ישיר וברור לחיפוש (אם כי באופן עקיף, כמובן שיש קשר עמוק) - כיווץ טקסט, ולכן כיווץ בכלל. על כך - בפעם הבאה.