מה זה אומר ש-MIP*=RE? (חלק א': מה זה אומר RE?)
ממש לא מזמן התבשרנו על תוצאה בתורת הסיבוכיות שמנוסחת בפשטות בתור \( \text{MIP}^{*}=\text{RE} \). התגובה הראשונה שלי לתוצאה הייתה “מה?” והתגובה השניה שלי לתוצאה הייתה “מה?!?!”. בפוסט הזה אנסה להסביר מה.
ראשית המאמר עצמו זמין כאן ואפשר לקרוא אותו. אני לא קראתי אותו מלבד את הפתיחה שלו - הוא כולל 165 עמודים ואין לי סיכוי להבין את הפרטים הטכניים שלו לעומק - אבל אני מקווה שאני מבין מספיק טוב את הרקע כדי להסביר בערך מה המשפט אומר ולמה הוא מעניין. בפשטות, הוא אומר שמערכת הוכחה מסויימת שמתבססת בצורה כלשהי על אפקטים קוונטיים, היא חזקה בצורה מטורפת ממש ביחס למערכת הוכחה הדומה לה מאוד שאינה מתבססת על אפקטים קוונטיים. זה משהו שהפתיע קצת את אלו שהכירו את התחום וידעו שהמערכת הזו חזקה בצורה מטורפת; אותי, שבכלל לא ידע על כל זה, זה פשוט הדהים.
אז בואו ננסה להבין מה הולך כאן. לאט.
הפעם אני אסביר מה זו \( \text{RE} \). יש לי פוסט על זה מראשית ימי הבלוג, אבל אני אנסה הפעם להציג את המושג מכיוון קצת שונה, שיעזור לנו גם בהמשך כשנדבר על \( \text{MIP}^{*} \), כך שאני חושב ששווה לנסות לקרוא גם אם כבר מכירים את \( \text{RE} \).
בואו נתחיל עם משחק הסודוקו שאני מקווה שמוכר ואהוב על כולנו. או לפחות מוכר.
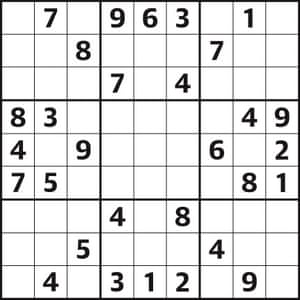
הרעיון בסודוקו פשוט יחסית: נתון לוח של \( 9\times9 \) משבצות שמחולק גם ל-9 תת-לוחות, כל אחד של \( 3\times3 \). בלוח מופיעים כל מני מספרים בין 1 ל-9, והמטרה היא להשלים את הלוח כך שבכל משבצת יהיה מספר בין 1 ל-9 ובנוסף לכך בכל שורה, עמודה ותת-לוח כל המספרים שמופיעים יהיו שונים זה מזה. זה משחק פאזלים חביב בפני עצמו, אבל אני אוהב אותו מאוד בעיקר בגלל שהוא נותן לנו דוגמא יפה לבעיה מהסוג שאנחנו אוהבים לדבר עליהן במדעי המחשב התיאורטיים: בעיה שקשה לפתור אבל קל לוודא.
בסודוקו המטרה היא למצוא את הפתרון של הלוח, אבל גם אפשר להצטמצם לבעיה פשוטה יותר: נותנים לכם לוח סודוקו - כלומר, לוח \( 9\times9 \) שהוא כבר מלא חלקית במספרים - ושואלים אתכם אם הוא פתיר או לא. לא כל לוח ממולא חלקית הוא פתיר! שאלת “כן/לא” כזו נקראת במדעי המחשב בעיית הכרעה וזה מה שאנחנו בדרך כלל מעדיפים לדבר עליו, ולא על בעיית החיפוש של למצוא את הפתרון, כי על פי רוב אם יש לנו פתרון נחמד לבעיית ההכרעה אפשר גם לבנות בעזרתו פתרון לבעיית החיפוש. במקרה של סודוקו, למשל: בהינתן לוח תבדקו אם הוא פתיר - אם לא פתיר, אפשר לוותר על הכל. אם כן פתיר, אז פשוט תנסו למלא מספרים במשבצות ובכל פעם כזו תשאלו אם הלוח נשאר פתיר גם אחרי המילוי - אם לא, אתם יודעים שהמהלך האחרון שביצעתם היה שגוי וצריך לנסות אחר. זה יוביל אתכם די מהר לפתרון.
עכשיו, להכריע האם לוח סודוקו הוא פתיר יכול להיות עניין קשה לפעמים. יש היוריסטיקות טובות כדי למצוא פתרון, אבל בלוחות “קשים” יהיה צורך להתחיל לנחש איזה ערכים כדאי לשים במשבצות, ואם הניחוש היה לא מוצלח ייתכן שנצטרך לחזור הרבה אחורה בבדיקה שלנו כדי לתקן את זה, וכן הלאה. אז זו בעיית הכרעה שקשה לפתור לעומת זאת, אם מישהי באה אליכם וטוענת שהיא פתרה את הלוח כבר, קל לה מאוד להוכיח לכם את זה: היא פשוט תיתן לכם את הלוח הפתור. אתם תסתכלו על הלוח ותבצעו תהליך של וידוא שהלוח באמת חוקי (בכל שורה/עמודה/תת-לוח יש את כל המספרים מ-1 עד 9) ושהוא באמת מרחיב את הלוח שיש לכם (כל מספר שהופיע בלוח שלכם מופיע גם בלוח של הפתרון). זה לוקח מעט זמן יחסית. אם כן, לודא שמשהו הוא פתרון של הלוח - זה קל.
כשאני אומר “קשה” ו”קל”, למה אני מתכוון? עבורי לפתור סודוקו זה כאב ראש במוח - מרוב דברים לזכור או לרשום בצד, המוח שלי מתפוצץ. אבל עבור מחשב אין הרבה מה לרשום בצד ואין בעיה לזכור דברים - ה”משאב” שהמחשב משקיע הוא זמן. זה המשאב המרכזי שעליו מדברים בתורת הסיבוכיות - כמה צעדי חישוב בערך נדרשים בשביל לפתור בעיה.
יש עוד נקודה מהותית בהגדרה של “קל/קשה”. אם נסתכל על סודוקו של \( 9\times9 \), זו כנראה בעיה פתורה וסגורה כבר בימינו. אפילו במקרים הקשים ביותר, מחשב עם אלגוריתם סביר כנראה יוכל לפתור הכל (אני אומר “כנראה” כי אני מנחש, לא בטוח). מה שמעניין אותנו במדעי המחשב התיאורטיים הוא מה קורה ככל שמגדילים את הבעיה. קל להגדיל סודוקו - במקום לשחק אותו על לוח של \( 9\times9 \), לשחק אותו על לוח \( n^{2}\times n^{2} \) כללי (סודוקו רגיל הוא המקרה \( n=3 \)). אותם אלגוריתם שעובדים בלוח \( 9\times9 \) יעבדו גם בלוחות גדולים יותר, אבל ייקח להם יותר זמן. השאלה כמה יותר זמן. אם נכפיל את גודל הלוח פי 10, האם הזמן יגדל פי 10? פי 100? פי \( 2^{10} \)? אפשר לתת פונקציה \( f\left(n\right) \) שאומרת בערך מה זמן הריצה כפונקציה של גודל הקלט. אם זמן הריצה הוא בערך פולינום, אז אומרים שהאלגוריתם יעיל, ואם הוא גדול יותר מפולינום, נניח \( 2^{n} \), אומרים שהוא לא יעיל. אפשר להעלות הרבה השגות לגבי הגישה הזו אבל לא ניכנס לזה כאן - גם לא חייבים להבין עד הסוף את מה שאמרתי פה כדי להבין את ההמשך.
אני רוצה להכניס קצת פורמליזם לתמונה. בעיית הכרעה אני מסמן לרוב באות \( L \), ואת האלגוריתם שמנסה לפתור אותה אני מסמן ב-\( M \). ל-\( M \) נותנים קלט \( x \) כלשהו והוא עונה עליו “כן/לא”, מה שאסמן ב-\( M\left(x\right)=\text{T} \) ו-\( M\left(x\right)=\text{F} \). כדי לומר ש-\( M \) פותר את בעיית ההכרעה \( L \) אני רוצה שיתקיימו שני דברים שאני קורא להם “שלמות” ו”נאותות”:
- (שלמות) אם \( x\in L \) אז \( M\left(x\right)=\text{T} \).
- (נאותות) אם \( x\notin L \) אז \( M\left(x\right)=\text{F} \).
אם יש לנו \( M \) יעיל כזה, אומרים שהבעיה שייך ל-P (האות P היא מהמילה Polynomial)
לעומת זאת, מוודא \( V \) הוא משהו שקצת יותר קל לו בחיים: הוא מקבל קלט שהוא זוג \( \left(x,\pi\right) \). ה-\( x \) הוא כמו קודם, משהו שצריך לבדוק אם \( x\in L \) או לא. אבל \( \pi \) זו ה”הוכחה” לכך ש-\( x\in L \). \( \pi \) לא חייב להיות כתוב כמו הוכחה; אין שום דרישה על המבנה של \( \pi \), אבל כן יש דרישה שהוא לא יהיה ארוך מדי - האורך שלו צריך להיות פולינומי באורך של \( x \) אחרת מוודא שרץ בזמן פולינומי לא יוכל לקרוא את כולו ממילא.
כדי להגיד ש-\( V \) הוא מוודא תקין צריך שיתקיימו שני דברים:
- (שלמות) אם \( x\in L \) אז קיים \( \pi \) כך ש-\( V\left(x,\pi\right)=\text{T} \).
- (נאותות) אם \( x\notin L \) אז לכל \( \pi \) מתקיים \( V\left(x,\pi\right)=\text{F} \).
במילים אחרות, מוודא טוב הוא זה שמשתכנע מכל הוכחה נכונה אבל אם הטענה שגויה, שום הוכחה שקרית לא תשכנע אותו.
אם יש מוודא יעיל עבור \( L \) אומרים ש-\( L \) שייכת ל-\( \text{NP} \) (האותיות הללו הן מלשון Nondeterministic Polynomial שמגיעות מניסוח שקול ופחות מעניין של הגדרת המחלקה).
אחת השאלות הפתוחות המעניינות במדעי המחשב היא האם P=NP. האמונה של רובנו היא שזה לא נכון, אבל לא ארחיב על זה כאן. יש לי פוסט בנושא, למעוניינים.
עכשיו, אחרי שסיימנו להבין מה זה קל/קשה ומה זה P ו-NP. אני רוצה לזרוק את זה לפח לרגע. מה אם אנחנו לא מגבילים את משאבי החישוב שלנו בכלל? יש לנו רק דרישה אחת ויחידה מהאלגוריתם שלנו, אבל אחת שהיא עדיין משמעותית למדי - שיעצור מתישהו עם תשובה. כי אלגוריתמים שלא עוצרים בכלל זה עסק קצת בעייתי מבחינתנו. עכשיו, כזכור, מטרת האלגוריתם היא לוודא בעיית הכרעה כלשהי.
ההגדרות נשארות זהות למה שאמרתי קודם. אחזור עליהן כדי לחדד. \( L \) היא בעיית הכרעה כלשהי, \( x \) הוא קלט אליה, \( \pi \) הוא “הוכחה” ו-\( V \) הוא מוודא. אני משמיט את הדרישות שהזכרתי קודם על הסיבוכיות: \( V \) לא חייב לרוץ בזמן פולינומי, ו-\( \pi \) לא צריך להיות מוגבל באורכו בשום צורה.
עם ההגדרות הללו, כדי להגיד ש-\( V \) הוא מוודא תקין צריך שיתקיימו שני דברים:
- (שלמות) אם \( x\in L \) אז קיים \( \pi \) כך ש-\( V\left(x,\pi\right)=\text{T} \).
- (נאותות) אם \( x\notin L \) אז לכל \( \pi \) מתקיים \( V\left(x,\pi\right)=\text{F} \).
אם יש מוודא כזה עבור \( L \) אומרים ש-\( L \) שייכת למחלקה \( \text{RE} \). כן, זו ה-\( \text{RE} \) שבשוויון \( \text{MIP}^{*}=\text{RE} \). לא הגדרה כל כך קשה, נכון? הנה הגדרה אלטרנטיבית, שהיא אולי הנפוצה יותר: \( L \) שייכת ל-\( \text{RE} \) אם קיים אלגוריתם \( M \) כך ש:
- (שלמות) אם \( x\in L \) אז \( M\left(x\right)=\text{T} \).
- (נאותות חלקית) אם \( x\notin L \) אז או ש-\( M\left(x\right)=\text{F} \) או ש-\( M \) לא עוצרת על \( x \).
שימו לב מה השתנה פה: \( M \) היא לא מוודא אלא משהו שמנסה לפתור את הבעיה בלי לבדוק “הוכחה” כלשהי; אבל אנחנו מקלים מאוד את החיים של \( M \) בכך שאנחנו כן מרשים לו לא לעצור על קלטים מסויימים - כאלו שהתשובה להם היא “לא”. אם הייתי דורש נאותות מלאה - כלומר ש-\( M \) תעצור תמיד על קלט \( x\notin L \) ויתקבל \( \left(x\right)=\text{F} \)\( M \), אז זה היה מגדיר מחלקה אחרת, \( \text{R} \), שהיא האנלוג של \( \text{P} \) רק ללא דרישות סיבוכיות.
בניגוד לשאלת P=NP הפתוחה, שאלת R=RE אינה פתוחה כלל - אנחנו יודעים שהתשובה שלילית כי למשל טיורינג הוכיח את זה פשוט על ידי הדגמה מפורשת של בעיה ששייכת ל-RE אבל לא שייכת ל-R: “בעיית העצירה”.
בבעיית העצירה אנחנו מקבלים בתור קלט אלגוריתם \( M \) כלשהו (תניחו שהוא כתוב בשפת התכנות החביבה שלכם, או מתואר בתור מכונת טיורינג - זה לא משנה) וצריכים לקבוע האם כשמריצים אותו הוא עוצר או לא. רגע אחד, אפשר לשאול - מריצים את \( M \) על מה? בדרך כלל נותנים למשהו כמו \( M \) קלט. ובכן, מספיק לי לדבר על הוריאנט של בעיית העצירה שבו אין קלט (או שהקלט “ריק”). יש לי פוסט שמסביר מדוע בעיית העצירה לא שייכת ל-R ולא אחזור על זה כאן, אבל להראות שהיא שייכת ל-RE עם ההגדרה-מבוססת-מוודא שנתתי כאן, זה קל: \( V \) יקבל קלט \( \left(M,\pi\right) \). אם \( \pi \) הוא מספר טבעי \( n \), אז \( V \) יריץ את \( M \) במשך \( n \) צעדי חישוב. אם בפרק הזמן הזה \( M \) עצרה, נפלא! \( V \) יעצור ויגיד \( \text{T} \). אם לעומת זאת \( M \) לא עצרה, \( V \) יעצור ויגיד \( \text{F} \). עכשיו, מה קורה כאן?
אם \( M \) עוצרת, כלומר \( M\in L \), אז קיים \( n \) טבעי שהוא מספר הצעדים שנדרשים ל-\( M \) כדי לעצור. אז קיים \( \pi \) כך ש-\( V\left(x,\pi\right)=\text{T} \) - פשוט \( \pi \) שהוא מספר הצעדים \( n \). לעומת זאת, אם \( M\notin L \) אז לכל מספר צעדים שהוא, הרצת \( V \) על \( M \) לא תסתיים ולכן \( V \) תמיד תעצור ותחזיר \( \text{F} \) לכל \( \pi \), כולל \( \pi \)-ים שהם ג’יבריש ולא מספרים.
בואו נקבל שניה אינטואיציה למה בעיית העצירה היא עד כדי כך חזקה עד שהגיוני שלא יהיה אפשר לפתור אותה אלגוריתמית. ניקח לדוגמא את השערת גולדבך: לכל מספר זוגי \( n\ge4 \) קיימים שני ראשוניים \( p,q \) כך ש-\( n=p+q \). ההשערה הזו קיימת כבר מאות שנים וטרם נמצאה לה הוכחה או הפרכה. אם היינו יכולים לפתור את בעיית העצירה היינו מסוגלים להשתמש בפתרון הזה כדי לדעת האם השערת גולדבך נכונה או לא: היינו כותבים אלגוריתם \( M \) שפשוט רץ סדרתית על כל ה-\( n\ge4 \) הזוגיים, ולכל אחד מהם רץ על כל הראשוניים \( p<n \) ובודק האם \( n-p \) גם ראשוני. אם \( M \) מגלה \( n \) שעבורו לא קיים הפירוק \( n=p+q \) הזה, \( M \) עוצר. אחרת הוא עובר ל-\( n \) הבא בתור. כעת, אפשר לתת את \( M \) בתור קלט לבעיית העצירה. אם \( M\in L \) זה אומר ש-\( M \) עוצר ולכן השערת גולדבך לא נכונה (כי \( M \) מצא לה דוגמא נגדית). אחרת, אם \( M\notin L \), זה אומר ש-\( M \) לא עוצר ולכן השערת גולדבך נכונה. באופן דומה אפשר לנצל את בעיית העצירה כדי לפתור עוד בעיות; למעשה, אפשר להראות שכל בעיה ב-\( \text{RE} \) ניתנת לתרגום לא מסובך לבעיית העצירה, כך שאם נוכל לפתור את בעיית העצירה, נוכל לפתור כל בעיה אחרת ב-\( \text{RE} \) (בלשון שאולי אתם מכירים מתורת הסיבוכיות, בעיית העצירה היא \( \text{RE} \)-שלמה, בדומה לבעיות שהן \( \text{NP} \)-שלמות).
למה אני מדבר כל כך הרבה על בעיית העצירה? כי עיקר מה שעושים במאמר של \( \text{MIP}^{*}=\text{RE} \) הוא להוכיח את השייכות של בעיית העצירה ל-\( \text{MIP}^{*} \), מה שגורר כמעט מיידית את השוויון \( \text{MIP}^{*}=\text{RE} \). אם כן, הגיע הזמן שנדבר על מהי \( \text{MIP}^{*} \). זה מה שנעשה בפוסט הבא.
נהניתם? התעניינתם? אם תרצו, אתם מוזמנים לתת טיפ: